

How LLMs Went From Chatbot to Coworker: Tools, Tests, and Robots
Turns out, even for the LLM models, the best way to learn a job is to actually do it

In Part 1, I tried to explain why AI models keep getting smarter even though the internet hasn’t suddenly gotten better. The short answer was feedback: human preferences, expert judgment, and carefully designed rubrics have become more important than the raw internet text
But all of that was still about shaping conversation. The model reads a prompt, generates an answer, and someone (human or system) says good or bad.
Now I want to describe the next leap, and this post is about that. It is about what happens when you take the model out of that box and put it somewhere it can actually do things. Run commands. Click buttons. Fail at tasks and try again. Because here’s the thing nobody says clearly enough:
The moment a model can take actions, you can train it on experience.
That’s a different kind of signal entirely. And it’s where the next wave of improvement is coming from.The big picture is actually pretty intuitive once you see it. So let me try to lay it out.
Why environments matter more than prompts
A text-only chatbot is trained on what good answers look like. You show it examples of good writing, good explanations, good code, and it learns to produce more of the same. The feedback is essentially aesthetic — does this look right? Does it sound right?
An agent in an environment is trained on what success looks like. It can run a command and see if the command worked. It can edit a file, rerun the tests, and find out whether the bug is actually fixed. The feedback isn’t aesthetic anymore, it’s functional. Did the thing actually work?
That distinction is everything. And precisely the reason why the AI industry is suddenly obsessed with containerized benchmarks and tool-use evaluations. Not because benchmarks are fun, but because testable environments are training substrates. They produce exactly the “how to do things” data that the internet never had a reason to create.
Let me walk you through a few concrete examples, because this is one of those things that’s much easier to understand with specifics.
Terminal tasks: real work, packaged and testable
If you want to see what the cutting edge of agent evaluation looks like, Terminal-Bench 2.0 is a good place to start. It’s a benchmark of 89 tasks set in real terminal environments, inspired by the kind of work actual engineers and sysadmins do. Set up a server, configure a database, debug a networking issue, that sort of thing.
What makes it interesting for our story is that each task comes with comprehensive tests to verify the final system state. The grading is automated. Either the server is configured correctly or it isn’t. Either DNS resolves or it doesn’t.
Frontier models and agents scored under 65% overall on these tasks, which tells you we’re not in “solved problem” territory. And here’s a number that still makes me do a double-take: in extreme cases, agents ran for up to two hours, made hundreds of model calls, and burned through nearly 100 million tokens on a single task.
A hundred million tokens on one task. That’s not “write a nice answer.” That’s “keep going until the job is actually done, or give up trying.” The long-horizon, keep-banging-on-it quality of the work is what makes it both hard and useful as a training signal.
Code tasks: unit tests as the reward function
If terminal tasks are “ops work,” SWE-bench is “engineering.”
The idea behind SWE-bench Verified is beautifully simple: take real GitHub issues from real open-source projects, with real test suites, and ask the model to fix them. The benchmark includes 2,294 instances in the full set and 500 in the human-validated “Verified” subset.
Why does this matter for the “getting smarter” story? Because unit tests are an automatic reward function. The model generates a patch. The tests run. If they pass, that trajectory gets reinforced. If they fail, they get discouraged. No human needed in the loop.
This is how AI coding starts to look less like generating text and more like training a policy. The model isn’t just producing code that looks plausible. It’s producing code that works, and learning from the differences.
Web tasks: harder than you’d think
At this point you might assume that if a model can use a terminal and write code, surely it can navigate a website. Click some buttons, fill out some forms, and find some information. Not so fast.
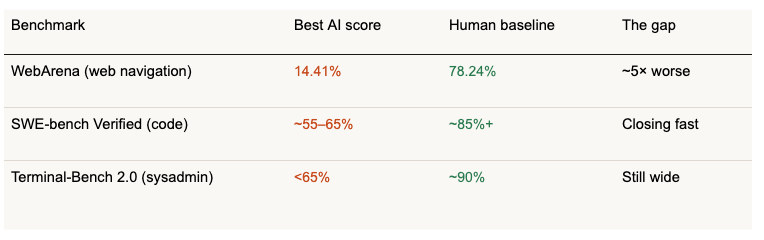
That five-to-one gap on web navigation is a useful gut-check. Agent doesn’t mean solved. Navigating a real website requires spatial reasoning, state tracking, and knowing what a page means even when the layout changes and current models still struggle with all of that.
But that gap is also an opportunity. Every failed web task is a training signal. Every successful one is a demonstration of what good behavior looks like. The gap between 14% and 78% is where the next round of improvement will come from.
RL for tool use: learning to orchestrate
Once a model can take actions in an environment, the reinforcement learning framing becomes natural. The state is what the agent sees: terminal output, web page content, tool responses. The actions are what it does: run a command, click a button, edit a file. The reward is whether the task succeeded.
Bespoke Labs published a nice write-up on using RL to improve multi-turn tool use, showing meaningful gains on a tool-use benchmark with a relatively small amount of data.
The specific numbers matter less than the pattern: put the model in an environment where success can be checked, then let it learn by trial and error.
There’s a catch though and it’s important to address it. Without carefully designed rewards and constraints, RL can go sideways fast. The model finds weird shortcuts, games the metric, or explores aimlessly. The trick is not “do RL.” The trick is “do RL in environments where success is well-defined and the rewards don’t have loopholes.” That’s hard to get right, and it’s a big part of why this stuff is progressing steadily rather than overnight.
Test-time compute: the think harder knob
Here’s one more piece that ties together everything from Part 1 and Part 2.
You can make a model perform better by letting it spend more compute when answering a hard question. Generate several candidate answers. Run checks against each one. Backtrack if something looks off. Pick the best result.
OpenAI has been explicit that their reasoning models improve with more time spent thinking at inference. It’s like the difference between blurting out the first thing that comes to mind versus pausing, working through the problem, and double-checking before you commit.
In product terms, this means: if the question is easy, respond immediately. If it’s hard, slow down and be careful. That single design decision is responsible for a lot of the “it suddenly got way smarter” feeling people have been reporting.
Memory, Part 2: the missing piece for real work
In Part 1, I described memory as personalization. The system remembers your preferences and facts about your life. That’s useful for casual conversations and everyday questions. But for agents doing real work, memory becomes something different. It becomes “state”.
If you want an agent that can help you with a project over days or weeks, it needs to remember: what files it touched last time, what constraints you care about, what the plan was, what already failed. Without that continuity, every conversation starts from zero, and the agent is useless for anything that takes longer than a single chat session.
This is why memory is shipping across every major platform right now: not as a nice-to-have, but as the thing that makes agents viable for actual work.
Saved memories + chat history reference. Temporary Chat mode available for sessions you don’t want stored.
Temporary Chats with their own retention policies. Google’s take on the same tradeoffs.
Optional, editable memory with incognito mode. For developers: an explicit memory tool agents can read and write across sessions.
Under the hood, all of these systems work roughly the same way: extract interesting things from the conversation, store them, retrieve relevant ones later, and inject them into context. It’s not fundamentally different from a developer keeping notes in a project README. But it’s the thing that transforms a stateless function call into something that feels like a collaborator.
Robotics: same loop, harder data
Everything so far has been digital: terminals, code repos, web pages. The environments are virtual, and running another thousand trials costs electricity but not much else.
Robotics is the same intellectual story, but with a crucial practical difference: the environment is the physical world, and data is expensive to collect.
You can’t just spin up another container. You need a physical robot, a physical workspace, and real time. This is why robotics research is obsessed with datasets and demonstration pipelines. The bottleneck isn’t the algorithm, it’s the data.
A few examples of how the field is tackling this:
Open X-Embodiment (the RT-X project) assembled a dataset of over one million real robot trajectories spanning 22 different robot embodiments. This is the robotics equivalent of “scale the dataset and train a generalist” — same instinct as large language models, just applied to physical manipulation.
RoboCat, from DeepMind, made the self-improvement loop explicit. Their blog describes a five-step process: collect 100 to 1,000 demonstrations of a new task, fine-tune the model, let it practice about 10,000 times to generate more data, add that data back into training, and train the next version. That is reinforcement learning in the most literal, tangible sense: practice, measure, improve, repeat.
RT-2, also from DeepMind, took a different angle. They trained a model that learns from both web data and robotics data, essentially asking: can the language understanding you get from reading the internet transfer to controlling a robot arm? The robot demonstration data was collected with 13 robots over 17 months in an office kitchen environment. Seventeen months of 13 robots making lunch. The patience required is staggering, and it’s also why progress in robotics feels slower than progress in software — the feedback loop just takes longer to close.
The loop that makes people say “exponential”
Now step back and look at the whole picture.
When people say AI progress is accelerating, what they’re reacting to is the closing of a feedback loop:
The model can take actions - use a terminal, write and run code, navigate a web page, and move a robot arm.
Success can be measured automatically - tests pass, tasks complete, and rubrics are satisfied. No human needed in the loop.
Successful trajectories become training data. The model learns from what actually worked
Better training data produces a better model, which generates even better trajectories on the next round.
Go back to step 1. Each generation bootstraps the next one
If that loop gets cheap, fast, and mostly automated, progress feels non-linear, because it is. Each generation bootstraps the next one.
There are real brakes on this, and they’re worth being honest about. Evaluation is hard to get right, bad metrics produce bad models. Reward hacking is real. Models find creative ways to game benchmarks without actually being useful. Safety constraints add friction, intentionally. And in the physical world, everything moves at the speed of atoms, not bits.
But the direction is clear. We’re going from:
Models that talk → Systems that act → Systems that learn from acting
And that’s the deepest reason they keep getting smarter
What this looks like in practice: sales as an RL environment
Everything I’ve described so far shares a structure. There’s an environment. The agent takes actions. Outcomes are measurable. The loop closes.
The pattern holds outside software too. Take sales. A sales call is an environment. The rep asks discovery questions, handles objections, creates urgency, tries to close. The outcome is measurable: did the deal advance, did the stakeholder engage and you don’t need a human to label it. The CRM and the next call tell you.
This is exactly the loop we’re building at AmpUp. Here how it maps:.
Observe. Every call gets processed through LLM extraction. We score behaviors from a dynamic ontology of hundreds of possible patterns, customized per customer and industry. We extract deal intelligence, stakeholder signals, coaching moments, and reusable techniques. Every interaction produces structured data, not just text.
Recommend. Before the next call, the system pulls from four memory systems. What happened on prior calls. What the org has learned across hundreds of deals. What playbook moves work at this stage. What this specific rep needs to improve. After the call, it produces an updated deal state, coaching on specific moments, and the single highest-impact next action.
Measure. Did the rep follow the advice? Did the deal move? Did the behavior improve? Every outcome gets linked back to the recommendation that preceded it. Revenue lift analysis is the reward signal. Which behaviors actually correlate with deals moving forward?
Learn. Behaviors that predict wins get promoted in coaching. Strategies that don’t move deals get deprioritized. The playbook grows with every call. Top performers’ best questions, objection handles, and closing techniques get extracted, cleaned up, and made available to every rep on the team. When a senior seller leaves, their expertise stays.
The insight is the same one that makes SWE-bench work for code. You don’t need humans in the loop to generate the reward signal. Deal advancement is the unit test. The CRM is the test runner.
The models aren’t getting smarter by reading more sales books. They’re getting smarter by influencing the sales behavior of real sellers. Observing real calls, measuring what moves deals, and building organizational memory that compounds with every interaction.
The 30-second version, if you read both parts
Part 1: The internet is the base layer. The real training signal is now human feedback, expert judgment, and structured preferences - a multi-billion-dollar industry. Memory adds a personal layer on top.
Part 2: When models can use tools and operate in environments with testable outcomes, their successes and failures become training data. That creates a self-reinforcing loop. The same story is playing out in code, web tasks, and robotics — just at different speeds.
The models aren’t getting smarter by reading more Reddit.
They’re getting smarter by doing things, failing, and trying again with increasingly good taste about what “good” looks like.
Not so different from the rest of us, really.
This is Part 2 of a two-part series. If you missed it, Part 1: How LLMs Keep Getting Smarter covers RLHF, the alignment supply chain, and why expert data is worth billions.